7 Octoparse Alternatives: From DIY Scraping to Specialized Data Solutions (2026)
Octoparse has earned its reputation as one of the most accessible web scraping tools on the market. Its visual, point-and-click interface has opened up data extraction to marketers, researchers, and business analysts who would otherwise need to write code or hire developers. With over 100 preset templates, cloud extraction capabilities, and built-in anti-crawling protections, it offers a comprehensive toolkit for collecting web data.
But as your data needs evolve, you might find that a general-purpose scraping tool requires more time, technical effort, and ongoing maintenance than you bargained for. Building scrapers is one thing; keeping them running when websites change, matching products across platforms, and turning raw data into actionable intelligence is another challenge entirely.
That's where this guide comes in. Whether you're looking to:
-
Get e-commerce price intelligence without building and maintaining scrapers yourself
-
Access enterprise-grade proxy infrastructure for large-scale data collection
-
Build AI-powered applications that need web data as input
-
Find an affordable entry point for testing web scraping feasibility
-
Monitor website changes automatically with minimal maintenance
-
Gain complete developer control with open-source flexibility
-
Extract web content in formats optimized for language models
We'll explore dedicated Octoparse alternatives that excel in these specific areas.
Some businesses might use these tools alongside Octoparse to fill specific gaps, while others might replace it entirely with a solution better suited to their workflow. This isn't about finding a "better" tool; it's about finding the right fit for your specific needs and technical resources.
Let's dive into the Octoparse alternatives and see which ones might be the perfect addition to your data toolkit.
The Best Octoparse Alternatives
|
|
Starts at: €1,050/mo G2 Score: N/A Capterra Score: N/A |
GetRealPriceBest Alternative for E-commerce Price Intelligence Without the DIY Hassle We chose GetRealPrice because it transforms competitive pricing from a technical project into a strategic service. Instead of building scrapers, you get multi-layer product matching (combining AI with human verification), automated pricing recommendations, and competitor intelligence delivered to your dashboard. |
|
|
Starts at: $2.50/GB G2 Score: 4.6 Capterra Score: 4.7 |
Bright DataBest Alternative for Enterprise-Scale Data Infrastructure We chose Bright Data because its 150+ million residential IPs and developer-centric APIs provide the infrastructure foundation that enterprise teams need when Octoparse's IP rotation capabilities aren't sufficient for large-scale, blocking-resistant data collection. |
|
|
Starts at: $0 (Free tier) G2 Score: 4.7 Capterra Score: 4.8 |
ApifyBest Alternative for Growing Teams Needing Developer Flexibility and AI-Ready Data We chose Apify because its 10,000+ pre-built Actors and native AI framework integrations bridge the gap between no-code convenience and developer control, making it ideal for teams building LLM-powered applications. |
|
|
Starts at: $0 (Free tier) G2 Score: 4.3 Capterra Score: 4.5 |
ParseHubBest Alternative for Affordable Visual Scraping for Small Teams We chose ParseHub because its generous free tier (200 pages per run) and cross-platform desktop application make it an accessible entry point for small teams validating web scraping feasibility before committing budget. |
|
|
Starts at: $19/mo G2 Score: 4.8 Capterra Score: 4.6 |
Browse AIBest Alternative for No-Code Automation with AI Self-Healing We chose Browse AI because its AI-powered self-healing scrapers automatically adapt when websites change, dramatically reducing the maintenance burden that comes with Octoparse's selector-based approach. |
|
|
Starts at: $0 (Open Source) G2 Score: N/A Capterra Score: N/A |
ScrapyBest Alternative for Developers Who Want Full Control We chose Scrapy because Python developers gain unlimited customization and zero licensing costs with this production-proven framework, making it ideal for teams who find Octoparse's visual interface limiting. |
|
|
Starts at: $16/mo G2 Score: N/A Capterra Score: N/A |
FirecrawlBest Alternative for AI-Native Web Data Extraction We chose Firecrawl because it converts web content directly into LLM-ready Markdown, reducing token consumption by approximately 67% compared to raw HTML according to vendor benchmarks, making it purpose-built for AI engineers and RAG pipelines. |







What is Octoparse?
Octoparse is a no-code web scraping tool designed to extract data from websites and transform it into structured formats without requiring programming knowledge. The software simulates human browsing behavior, navigating websites, clicking elements, and collecting information through a visual, point-and-click interface.
Its key features include:
-
Workflow Designer: A visual interface where users click on web elements to build scraping logic, with AI-powered auto-detection that identifies lists, tables, and pagination automatically
-
Cloud Extraction: Run scraping tasks 24/7 on Octoparse's servers with automatic IP rotation, task scheduling, and concurrent processing across multiple cloud nodes
-
Preset Templates: Over 100 ready-to-use templates for popular websites like Amazon, LinkedIn, and Google Maps that require minimal configuration
-
Anti-Crawling Bypass: Built-in CAPTCHA solving, proxy support (both Octoparse's pool and custom proxies), and ad blocking to handle sites with anti-crawling protections
-
Flexible Data Export: Export to CSV, Excel, JSON, or directly to databases like MySQL and SQL Server, with API access for programmatic data retrieval
When you need to collect data from a website, Octoparse lets you visually select the elements you want, configure pagination and interactions, and run the task either locally or in the cloud. The platform handles many technical complexities of web scraping, from rendering JavaScript to configuring request delays.
Having a visual tool that handles these complexities makes web scraping accessible to non-developers.
But as data needs grow more specialized, particularly in areas like e-commerce competitive intelligence, AI application development, or enterprise-scale data collection, users often find they need either more specialized solutions or more powerful infrastructure than a general-purpose visual tool provides.
How We Curated Our List of Octoparse Alternatives
After testing Octoparse and researching the web scraping market, we focused on finding tools that address specific limitations users encounter as their needs evolve. While Octoparse is excellent for accessible, visual web scraping, businesses often need more specialized solutions for:
-
Getting competitive intelligence delivered as insights, not raw data requiring additional processing
-
Accessing enterprise-grade proxy infrastructure that can handle millions of requests without blocking
-
Building AI applications that need web data formatted for language models
-
Finding affordable entry points to validate scraping use cases before significant investment
-
Reducing ongoing maintenance when target websites frequently change their structure
-
Gaining complete programmatic control for complex, custom scraping requirements
Each tool on this list excels in one of these areas. You might want to use them alongside Octoparse or switch to them entirely, depending on what your growing data needs require.
|
❗DISCLAIMER: We aren't covering every web scraping tool on the market! Our focus is on highlighting the best alternatives that address Octoparse's limitations for specific use cases and business models. The goal is to help you find tools that match your particular requirements. |
|---|
1. GetRealPrice — Best Alternative for E-commerce Price Intelligence Without the DIY Hassle

GetRealPrice is a B2B price monitoring and competitive intelligence service built specifically for online retailers, marketplaces, and FMCG manufacturers.
Unlike Octoparse, which provides the tools to build your own scrapers, GetRealPrice delivers e-commerce intelligence as a turnkey solution. Its multi-layer matching process, combining AI with human verification, handles the complexity of matching products across different websites and provides actionable pricing insights.
Key capabilities include:
-
Multi-Layer Product Matching: A multi-step process where AI identifies potential matches by analyzing images, titles, descriptions, and attributes, followed by two levels of human verification to ensure accuracy. This approach matches both "duplicate" (same SKU) and "analog" (similar products with different packaging, colors, or brands) products, without requiring EAN codes or standardized identifiers
-
Competitor Monitoring: Tracks prices, stock availability, and promotions across competitors in any country and currency, with daily updates
-
Automated Pricing Recommendations: Translates your pricing strategy into rule-based actions that calculate optimal prices based on competitor data and your profit margin requirements
-
Competitor Turnover Analysis: Goes beyond stock tracking to estimate competitors' sales volumes and product turnover rates, providing strategic insight into market dynamics
-
Comprehensive Reporting: Over 1,820 report templates with customizable alerts delivered via email, plus API access for integration with ERP and e-commerce systems
GetRealPrice operates in 32 countries and serves retailers with product catalogs ranging from 5,000 to 19 million+ SKUs. For e-commerce businesses that need competitive pricing intelligence without the technical overhead of building and maintaining scrapers, GetRealPrice provides a turnkey solution.
Why Choose GetRealPrice Over Octoparse for E-commerce Price Intelligence
While Octoparse gives you the tools to extract data from websites, GetRealPrice gives you the intelligence you actually need to make pricing decisions. The fundamental difference is between a DIY tool and a purpose-built solution designed for a specific outcome.
Multi-Layer Product Matching: The Challenge Octoparse Can't Solve
The most significant gap between Octoparse and GetRealPrice isn't data extraction; it's product matching. When you scrape competitor websites with Octoparse, you get raw data: product names, prices, descriptions.
But how do you know which competitor product matches yours?
Product titles vary across retailers ("Apple iPhone 15 Pro 256GB" vs. "iPhone 15 Pro, 256 GB, Black" vs. "Apple iPhone15Pro 256"). Images differ. Descriptions use different formatting. Matching these requires advanced algorithms that understand product attributes, not just text comparison.
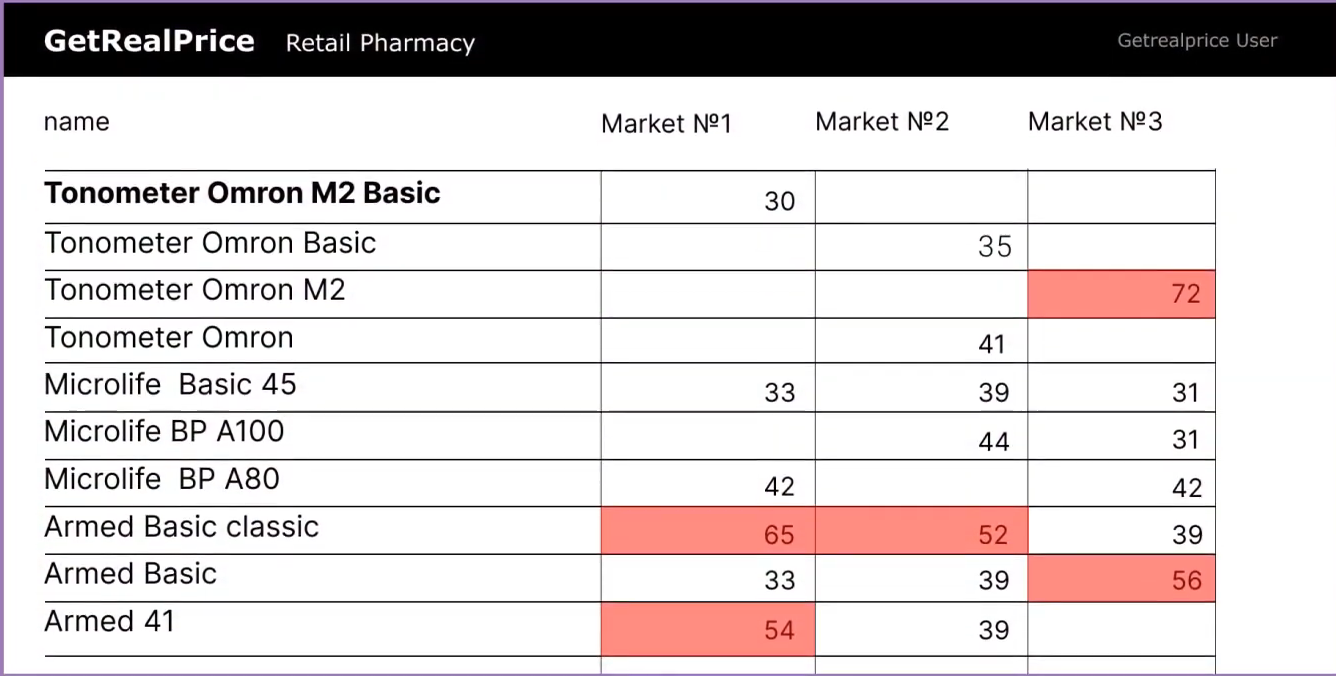
Source: GetRealPrice
GetRealPrice solves this with a multi-step verification process and two matching types:
-
Duplicate Matching: Finds identical SKUs across platforms, even when product information varies significantly, without requiring EAN codes, UPCs, or other standardized identifiers. The system only needs product names as input, then uses AI to analyze images, titles, and specifications
-
Analog Matching: Identifies similar products that serve as competitive alternatives, such as different packaging sizes, color variants, or comparable products from different brands. For example, the system can match a hexagon head bolt from one manufacturer with equivalent bolts from competitors based on shared parameters (material, size, specifications) even when product names are entirely different
What sets GetRealPrice apart is that AI matches undergo two levels of human verification. After the AI identifies potential matches, experienced specialists confirm or reject them, ensuring accuracy that purely automated systems cannot achieve. This human-in-the-loop approach delivers 98% matching accuracy.
With Octoparse, you would need to build the scraper, extract the data, and then develop your own matching logic, likely requiring significant development resources or manual effort. For a catalog of thousands of SKUs across multiple competitors, this becomes impractical.
⚡ GetRealPrice in Action: An online electronics retailer needs to monitor pricing for 50,000 SKUs across 15 competitors. With Octoparse, they would need to build 15 different scrapers, maintain them when sites change, and then somehow match products across different naming conventions and catalogs. With GetRealPrice, they upload their catalog, specify competitors, and receive matched pricing data in their dashboard, typically within days.
Data Collection Infrastructure: Handling Sites with Anti-Crawling Protections
While Octoparse includes IP rotation and CAPTCHA solving, GetRealPrice's infrastructure is purpose-built for reliable data collection at scale from even the most heavily protected websites. You not involved into creatring and supporting crawlers.
GetRealPrice's technical infrastructure includes:
-
Anti-Crawling Defense Bypass: Specialized technology for handling habitance tests, CAPTCHAs (using a combination of automated systems and human solvers at speeds up to 10,000 per hour), and sophisticated anti-bot measures
-
Visual Rendering Robots: Smart readers that imitate human-like behavior during browsing to avoid detection
-
Server Farm Infrastructure: Dedicated parsing infrastructure that can crawl data from standard websites, mobile applications, and sites with anti-crawling protections
When a target website changes its structure and breaks a crawler, GetRealPrice typically restores data collection within hours, not days. This reliability is critical for enterprise clients who require data delivered on strict schedules without exception.
Automated Pricing: From Data to Decisions
Octoparse stops at data extraction. What you do with that data is up to you. GetRealPrice extends beyond monitoring to automated pricing recommendations.
Typical Getrealprice dashboard daily results:
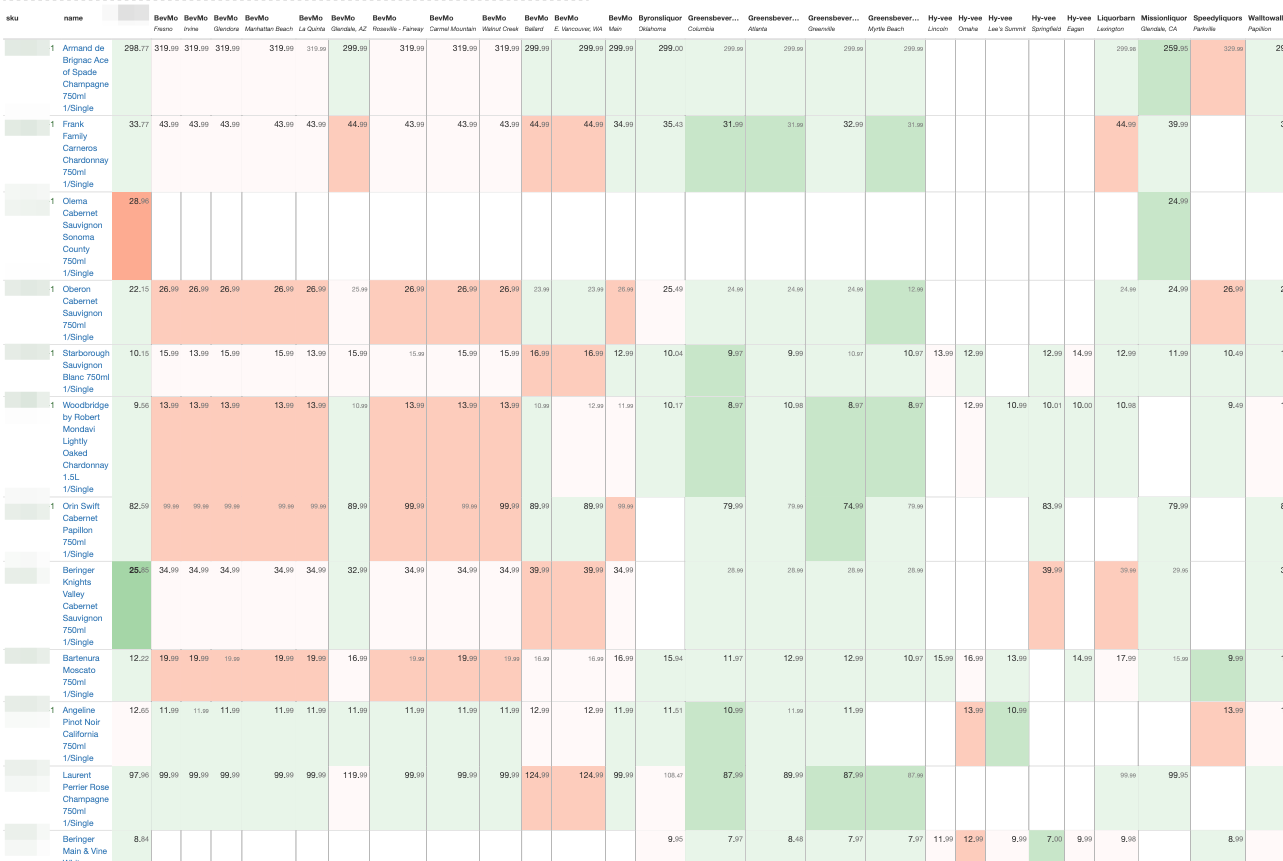
Source: GetRealPrice
The automated pricing feature allows you to define business rules that execute automatically.
For example, you can configure rules to match the lowest competitor price only when your profit margin stays above a certain threshold, stay a percentage below your primary competitor unless they're out of stock, or adjust prices based on competitor availability.
These rules execute daily based on fresh competitor data, and the API integration means prices can update automatically in your e-commerce platform. Notably, pricing recommendations use proven mathematical formulas rather than AI; this ensures pricing strategists can always explain why a specific price was recommended, providing the predictability and transparency that enterprise pricing teams require.
⚡ GetRealPrice in Action: A fashion retailer sets a rule to match their main competitor's price on seasonal items while maintaining a 10% margin minimum. When the competitor drops prices during a flash sale, GetRealPrice's system analyzes the new prices against margin thresholds and automatically adjusts the retailer's prices through their API connection, all without manual intervention.
Competitor Turnover Monitoring: Intelligence Beyond Prices
GetRealPrice offers a capability that would be difficult to replicate with standard scraping tools out of the box: competitor turnover monitoring. By analyzing stock level changes alongside pricing data, the system estimates how quickly competitors are selling products.
This provides strategic intelligence:
-
Identify which competitor products are selling fastest
-
Understand seasonal demand patterns in your market
-
Spot products where competitors are struggling (high stock, dropping prices)
Octoparse can track stock availability (in stock/out of stock), but calculating turnover rates requires continuous monitoring, historical analysis, and correlation with pricing data, functionality that would require significant custom development.
The Maintenance Factor
Perhaps the most underappreciated difference is ongoing maintenance. Octoparse users know the frustration: you build a scraper, it works perfectly, and then the target website changes its HTML structure and everything breaks.
GetRealPrice handles data collection as part of the service. When websites change, their engineering team updates the data collection. You receive consistent, accurate data without troubleshooting broken scrapers.
🏅 NOTE: We also evaluated dedicated price monitoring tools like Prisync and Price2Spy for this category. While Prisync offers a user-friendly interface suitable for smaller catalogs, and Price2Spy provides extensive customization for enterprises, GetRealPrice differentiates with its multi-layer human-verified matching process, ability to match products without standardized identifiers, and scalability for catalogs up to 19 million+ SKUs.
GetRealPrice Pricing
GetRealPrice uses an all-inclusive subscription model with pricing that scales based on the number of SKUs monitored and competitors tracked. Unlike usage-based pricing models common in the scraping industry, GetRealPrice includes all data traffic in the subscription, no variable costs or surprise charges.
-
Starter Package: Starting at €1,050/month
-
Monitor up to 4 competitor webshops
-
Price matching for up to 10,000 SKUs per competitor
-
Price updates up to 3 times per week
-
Access to ~100 report templates
-
2 hours of support consultation per week
-
All traffic included, no additional data costs
-
One-month WebApp trial included
-
Enterprise and custom packages are available for larger catalogs and more competitors. GetRealPrice offers extended pilot programs that can run for months with a close-to-commercial setup, allowing prospective clients to thoroughly evaluate the platform with real data before committing.
Who Should Use GetRealPrice?
Choose GetRealPrice if:
-
You're an online retailer who needs competitive pricing intelligence but lacks the technical resources to build and maintain scrapers. GetRealPrice delivers matched competitor data and pricing recommendations as a complete solution.
-
You manage a large product catalog (thousands to millions of SKUs) and need to track competitors across multiple markets. The platform's scalability and human-verified product matching handle complexity that would be impractical to manage with manual scraping.
-
Your products lack standardized identifiers like EAN codes. GetRealPrice's matching works from product names and attributes alone, making it suitable for categories where universal product codes aren't consistently used.
-
You want to implement dynamic pricing strategies based on competitor behavior. The rule-based repricing engine and API integration allow automated price adjustments that respond to market conditions daily.
-
You're an FMCG manufacturer needing to monitor reseller pricing compliance. GetRealPrice helps track whether retailers are adhering to recommended prices across your distribution network.
Want competitive pricing intelligence without the technical overhead? GetRealPrice transforms competitor monitoring from a DIY project into strategic insights delivered to your dashboard. Request a demo to see how human-verified product matching and automated pricing can work for your catalog.
2. Bright Data — Best Alternative for Enterprise-Scale Data Infrastructure

Bright Data is a comprehensive web data platform that represents a fundamentally different approach than Octoparse.
Where Octoparse provides a visual, no-code scraping tool, Bright Data delivers enterprise-grade data infrastructure built around one of the world's largest proxy networks: over 150 million residential IP addresses spanning 195 countries.
Key capabilities include:
-
Massive Proxy Network: 150+ million residential IPs, plus datacenter, mobile, and ISP (static residential) proxy pools, enabling successful extraction from heavily protected websites
-
Web Unlocker and Scraping Browser APIs: AI-powered tools that automatically handle CAPTCHAs, browser fingerprinting, and sophisticated anti-bot measures
-
Web Scraper IDE: A cloud-based JavaScript development environment with 70+ pre-built templates for major websites
-
Dataset Marketplace: 190+ ready-to-use datasets from over 120 domains, eliminating scraping entirely for common data needs
-
Enterprise Compliance: ISO 27001 certified with GDPR/CCPA compliance and ethically-sourced IPs through voluntary opt-in networks
Bright Data is positioned for enterprise clients and developer teams who require maximum control, scalability, and reliability; organizations willing to invest significantly more budget in exchange for infrastructure that handles virtually any target website at any scale.
Why Choose Bright Data Over Octoparse for Enterprise Data Infrastructure
Bright Data addresses limitations that enterprise teams encounter when Octoparse's capabilities aren't sufficient:
-
Infrastructure Scale That Overcomes Blocking
The most common frustration with Octoparse at scale is IP-based blocking. While Octoparse includes IP rotation in its cloud extraction, it operates from a limited pool.
Bright Data's 150+ million residential IPs appear as genuine consumer connections, dramatically reducing block rates. The platform achieves 98-99% success rates on residential proxies specifically because of this massive, ethically-sourced network.
For organizations whose Octoparse tasks frequently fail on sites with anti-crawling protections like Amazon or social platforms, Bright Data's infrastructure represents a fundamental capability upgrade.
-
Developer-Centric Architecture
Octoparse's strength (visual, no-code interface) becomes a limitation for complex requirements. Bright Data provides JavaScript-based development tools, comprehensive APIs, and integration with Puppeteer, Playwright, and Selenium.
Developers can implement arbitrarily complex scraping logic and integrate data collection directly into existing engineering workflows. The trade-off is clear: Bright Data requires development resources but removes the constraints of visual tools.
-
Enterprise Compliance Requirements
Bright Data holds ISO 27001 certification, maintains GDPR and CCPA compliance, enforces Know Your Customer (KYC) verification, and sources residential IPs through voluntary, AppEsteem-certified opt-in networks. For organizations in regulated industries with procurement processes requiring vendor security certifications, this compliance posture may be decisive.
🏅 NOTE: We also evaluated Oxylabs and Zyte for this category. While Oxylabs offers competitive proxy networks with strong performance (and claims an even larger residential IP pool), and Zyte provides excellent Scrapy integration, Bright Data offers a highly comprehensive platform combining proxies, APIs, IDE, and datasets with robust enterprise support infrastructure.
Bright Data Pricing
Bright Data uses usage-based, pay-as-you-go pricing:
-
Residential Proxies: Starting from $2.50/GB (volume discounts from base $5.00/GB)
-
Datacenter Proxies: Starting from $0.90/IP
-
Web Unlocker API: Starting from $1.00 per 1,000 results at higher volume tiers (pay-as-you-go starts at $1.50)
-
Scraper APIs: Starting from $0.75 per 1,000 records
-
Ready-to-use Datasets: Starting from $250 per 100,000 records
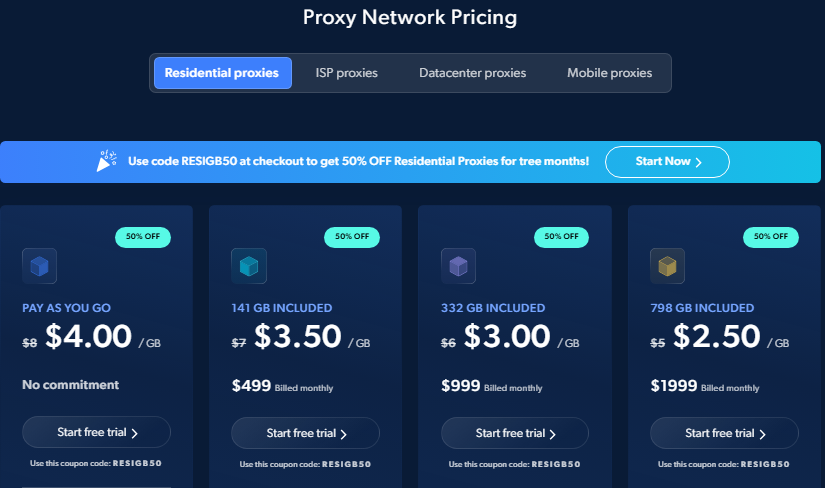
Source: Bright Data
Who Should Use Bright Data?
Choose Bright Data if:
-
Your organization has development resources and requires maximum flexibility. The API-first architecture requires technical expertise but provides capabilities no visual tool can match.
-
You're experiencing consistent blocking with Octoparse on protected targets. The 150M+ IP network with automatic CAPTCHA solving addresses blocking problems at the infrastructure level.
-
Compliance and security certifications are procurement requirements. ISO 27001, GDPR/CCPA compliance, and ethical IP sourcing documentation meet enterprise vendor review standards.
3. Apify — Best Alternative for Growing Teams Needing Developer Flexibility and AI-Ready Data
Apify is a full-stack web scraping and automation platform that bridges the gap between no-code tools and developer frameworks.
Its marketplace contains over 10,000 pre-built "Actors" (serverless cloud programs) that non-technical users can configure and run, while developers can build custom solutions using JavaScript or Python with the open-source Crawlee library.
Key capabilities include:
-
10,000+ Pre-built Actors: Ready-made scrapers covering virtually every major website, from Google Maps to Amazon to TikTok, configurable without coding
-
Open-Source Developer Tools: Build custom Actors using Crawlee (Apify's open-source library) with Puppeteer, Playwright, or Scrapy integration
-
Native AI/LLM Integrations: Direct connectors for LangChain, LlamaIndex, and vector databases, purpose-built for RAG pipelines and AI applications
-
Usage-Based Pricing: Prepaid credits that can be spent on any platform service, more economical for variable workloads
-
SOC 2 Type II Certified: Enterprise security compliance with notable customers including Microsoft and the European Commission
Why Choose Apify Over Octoparse for Growing Teams and AI Workflows
Apify stands out from Octoparse in several ways:
-
Dramatically Larger Marketplace
Octoparse offers over 100 preset templates. Apify's Store contains over 10,000 Actors covering an extraordinarily wide range of websites and use cases. The marketplace operates as a two-sided ecosystem where independent developers contribute and maintain Actors, creating an ever-growing library.
For teams that frequently scrape diverse sources, this breadth dramatically reduces time-to-data.
-
True Coding Flexibility
When Octoparse users encounter websites that don't fit the visual workflow paradigm, options are limited. Apify allows developers to write custom logic using familiar tools (Puppeteer, Playwright, Scrapy) with the open-source Crawlee library. Technical teams can implement complex scraping logic that visual tools simply cannot accommodate.
-
Purpose-Built for AI Applications
Apify has strategically positioned itself as infrastructure for AI applications, with native integrations for LangChain, LlamaIndex, and vector databases.
Support for Anthropic's Model Context Protocol allows LLMs to use Apify Actors as external tools. For teams building AI agents, RAG pipelines, or applications needing real-time web data for language models, this positioning makes Apify a natural fit.
🏅 NOTE: We also evaluated ScrapingBee and Zyte for this category. While ScrapingBee excels at API simplicity for developers needing rendered HTML, and Zyte offers strong managed services, Apify provides the most complete combination of marketplace convenience and developer flexibility for growing teams.
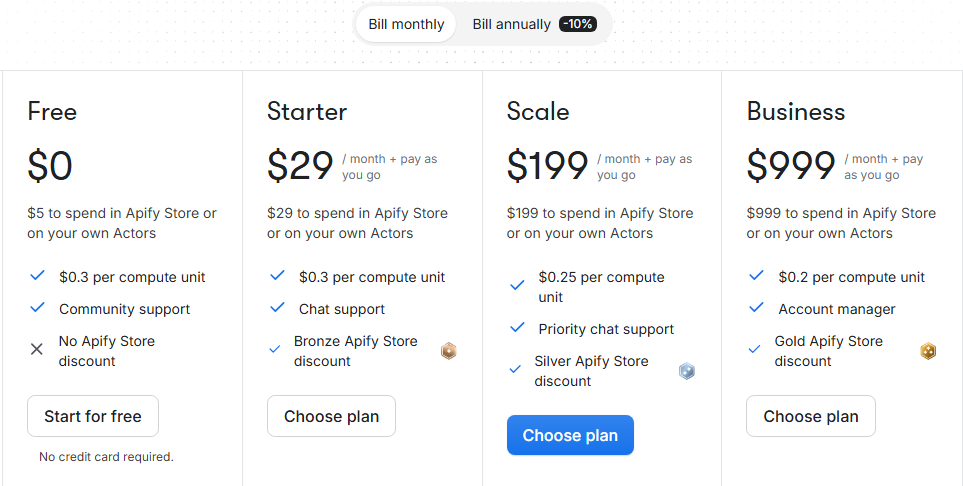
Apify Pricing
Apify uses a subscription-plus-usage model with prepaid credits:
-
Free: $0/month with $5 prepaid credits, 8 GB Actor RAM, community support
-
Starter: $29/month with $29 credits, 32 GB RAM, chat support
-
Scale: $199/month with $199 credits, 128 GB RAM, priority support
-
Business: $999/month with $999 credits, dedicated account manager
Source: Apify
Who Should Use Apify?
Choose Apify if:
-
You need access to a massive library of pre-built scrapers. The 10,000+ Actors cover nearly every popular website, reducing time-to-data for diverse scraping needs.
-
Your team includes developers who want to build or customize scrapers. Crawlee and support for JavaScript/Python give technical teams complete flexibility.
-
You're building AI applications that need web data. Native integrations with LangChain, LlamaIndex, and vector databases make Apify specifically suited for RAG pipelines and LLM-powered applications.
4. ParseHub — Best Alternative for Affordable Visual Scraping for Small Teams
ParseHub is a visual web scraping tool founded in 2013 that emphasizes accessibility and affordability.
Like Octoparse, it offers a point-and-click interface for building scrapers without code. Its key differentiator is a generous free tier and cross-platform support that makes it particularly suitable for small teams validating scraping feasibility.
Key capabilities include:
-
Generous Free Tier: 200 pages per run and 5 projects at no cost, no credit card required
-
Cross-Platform Desktop Application: Native apps for Windows, Mac, and Linux
-
Pattern Recognition: Automatically identifies similar elements after one or two selections
-
Handles Dynamic Content: Capable of scraping JavaScript-rendered pages, infinite scroll, logins, and pop-ups
-
Cloud-Based Scheduled Runs: Automate recurring scrapes without keeping your computer running
Why Choose ParseHub Over Octoparse for Affordable Visual Scraping
ParseHub appeals to small teams for several reasons:
-
More Accessible Free Tier
While both tools offer free plans, ParseHub's approach is "full capability, limited volume." The free plan includes the complete visual interface and handles dynamic websites; you're limited only in pages per run (200) and projects (5).
This allows small businesses to fully validate whether web scraping works for their use case before spending money. Octoparse's free plan limits execution to local devices only and provides only self-support.
-
True Cross-Platform Support
ParseHub provides native applications for Windows, macOS, and Linux, ensuring team members can work regardless of operating system. This is practical for startups and small businesses where employees may use personal devices or where Mac adoption is common in certain roles.
-
Pattern Recognition
After selecting one or two examples, ParseHub's recognition engine identifies similar elements automatically. This adaptive approach can be more flexible than template libraries when scraping less common websites or custom web applications.
🏅 NOTE: We also evaluated Browse AI and Webscraper.io for this category. While Browse AI excels at AI-powered automation with minimal setup, and Webscraper.io is a lightweight browser extension option, ParseHub offers the most compelling combination of a generous free tier with robust capabilities for handling complex dynamic sites.
ParseHub Pricing
-
Free: $0/month, 200 pages/run, 5 projects, 14-day data retention
-
Standard: $189/month, 10,000 pages/run, 20 private projects, IP rotation
-
Professional: $599/month, unlimited pages, 120 projects, priority support
-
ParseHub Plus: Custom pricing for fully managed service

Source: ParseHub
Who Should Use ParseHub?
Choose ParseHub if:
-
You need to validate web scraping feasibility before committing a budget. The generous free tier allows substantial testing without financial risk.
-
Your team lacks coding skills but needs data from complex websites. The visual interface handles JavaScript-heavy sites, logins, and infinite scroll without code.
-
You operate in a mixed-OS environment. Native applications for Windows, Mac, and Linux accommodate diverse team hardware.
5. Browse AI — Best Alternative for No-Code Automation with AI Self-Healing
Browse AI is a cloud-based, no-code web scraping platform that differentiates itself through AI-powered adaptability. Where Octoparse relies on CSS selectors and XPath that break when websites change, Browse AI's "self-healing" technology attempts to understand the contextual meaning of data rather than just its technical location.
Key capabilities include:
-
AI Self-Healing Scrapers: Robots use AI to recognize data context and structure, automatically adapting when websites change layouts
-
Built-In Website Monitoring: Schedule checks as frequent as every 5 minutes (on paid plans) with email notifications when content changes
-
7,000+ Application Integrations: Native connections through Zapier, Make.com, and Pabbly Connect, plus direct integrations with Google Sheets and Airtable
-
2-Minute Robot Training: Point-and-click setup with pre-built robots for 250+ popular websites
-
Cloud-Only Deployment: No software installation required; works from any browser
Why Choose Browse AI Over Octoparse for Self-Healing Automation
Browse AI addresses key pain points with traditional scrapers:
-
Reduced Maintenance Through AI Adaptation
Traditional scrapers, including Octoparse's templates, rely on selectors that break when websites update their HTML structure.
Browse AI's self-healing technology understands what data means, not just where it's located. When a website redesigns, robots often continue functioning without intervention. While no automated system achieves perfect reliability, this approach meaningfully reduces ongoing maintenance.
-
Native Website Monitoring
Octoparse is fundamentally a data extraction tool that can be scheduled. Browse AI treats website monitoring as a first-class feature, with configurable change detection for text, lists, and visual elements, adjustable sensitivity thresholds, and automated notifications. Users who need both extraction and change alerts don't need to cobble together separate tools.
-
Extensive Integration Ecosystem
Browse AI's 7,000+ application connections through multiple automation platforms (Zapier, Make.com, Pabbly Connect) provide extensive connectivity. Notably, these integrations are available on all plans including free, whereas Octoparse reserves some integrations for higher tiers.
🏅 NOTE: We also evaluated Bardeen and Gumloop for this category. While Bardeen excels at browser-based workflow automation for sales and recruiting, and Gumloop is emerging as a visual automation builder, Browse AI offers the most complete combination of self-healing scraping, monitoring, and integration capabilities.
Browse AI Pricing
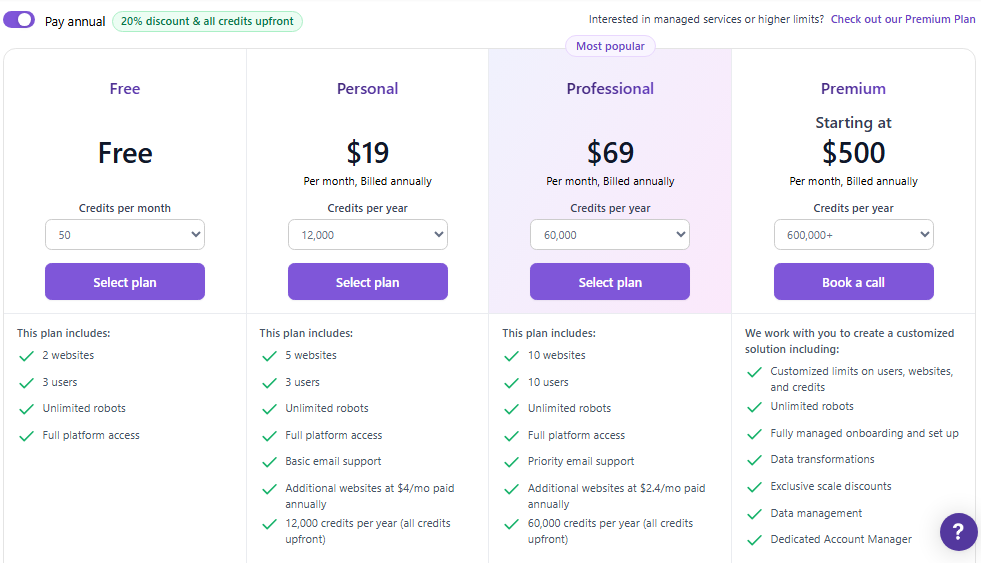
Browse AI uses a credit-based model (1 credit = 10 rows of data or 1 screenshot):
-
Free: $0/month, 50 credits, 2 websites, hourly monitoring minimum
-
Personal: $19/month (annual), 2,000 credits, 5 websites, 5-minute monitoring
-
Professional: Starting at $69/month (annual), 5,000+ credits, 10 websites, priority support
Source: Browse AI
Who Should Use Browse AI?
Choose Browse AI if:
-
You need scrapers that maintain themselves. AI-powered layout adaptation reduces maintenance overhead compared to Octoparse's selector-based approach.
-
Website change monitoring is as important as data extraction. Native monitoring with configurable sensitivity and notifications provides capabilities that would require additional tooling with Octoparse.
-
Your workflows depend on extensive integrations. The 7,000+ connections through multiple automation platforms, available on all plans including free, offer broad connectivity.
6. Scrapy — Best Alternative for Developers Who Want Full Control
Scrapy is a free, open-source Python web crawling framework that represents the opposite end of the spectrum from Octoparse. Where Octoparse prioritizes accessibility through its visual interface, Scrapy prioritizes power and flexibility for developers willing to write code.
Key capabilities include:
-
Completely Free and Open-Source: BSD license with no subscription fees, usage limits, or per-page charges
-
Asynchronous Architecture: Built on Twisted for non-blocking I/O, handling hundreds of concurrent connections efficiently
-
Full Customization: Complete control through Spiders, Pipelines, and Middlewares for request handling, data processing, and storage
-
Extensible Plugin Ecosystem: Libraries for proxy rotation, browser automation (scrapy-playwright), and distributed scraping (scrapy-redis)
-
Production-Proven: Maintained by Zyte with 59,400+ GitHub stars; used by companies like Parse.ly and Lyst
Why Choose Scrapy Over Octoparse for Developer Control
Scrapy serves a fundamentally different audience than Octoparse:
-
Zero Cost at Any Scale
The most fundamental difference is economic: Scrapy is free. Octoparse's pricing starts at $69/month for Standard and escalates to $249/month for Professional. For development teams running continuous, large-scale scraping operations, Octoparse costs accumulate significantly.
Scrapy eliminates licensing fees entirely, with no artificial limits on tasks or data exports.
-
Superior Performance Through Async Architecture
Scrapy's Twisted-based engine processes requests asynchronously, handling hundreds of simultaneous connections. While Octoparse's cloud extraction can split tasks across servers, it still operates within visual tool constraints.
Scrapy's architecture provides the foundation for high-performance scraping that can be extended with scrapy-redis for distributed crawling across multiple machines.
-
Complete Customization
Octoparse's visual interface, while accessible, limits flexibility. Scrapy provides unlimited customization through Downloader Middlewares, Spider Middlewares, Item Pipelines, and custom selectors. Developers can implement any scraping logic, handle edge cases programmatically, and integrate with existing systems.
🏅 NOTE: We also evaluated Beautiful Soup (with Requests) and Playwright standalone. While Beautiful Soup excels at simple HTML parsing with minimal setup, and Playwright is powerful for JavaScript-heavy sites, Scrapy offers the most complete free framework specifically designed for web scraping at scale.
Scrapy Pricing
-
Self-Hosted: $0 (framework is free; infrastructure costs apply)
-
Zyte Scrapy Cloud: Starting at ~$9/month per computing unit for managed deployment
Who Should Use Scrapy?
Choose Scrapy if:
-
You have Python development resources. Scrapy requires coding proficiency but unlocks capabilities that visual tools cannot provide.
-
You need maximum performance for large-scale or continuous scraping. The asynchronous architecture handles concurrent requests efficiently.
-
You want to eliminate subscription costs. Zero licensing fees mean your only costs are infrastructure and development time.
-
You require deep customization or integration. Programmable architecture accommodates complex scraping logic and system integration.
7. Firecrawl — Best Alternative for AI-Native Web Data Extraction
Firecrawl is a Y Combinator-backed web data extraction platform built specifically for AI and LLM applications. Instead of outputting raw HTML or traditional structured data, Firecrawl converts web content directly into LLM-ready formats like Markdown and structured JSON.
Key capabilities include:
-
Clean Markdown Output: Converts websites to LLM-ready Markdown, reducing token consumption by approximately 67% compared to raw HTML according to vendor benchmarks
-
Natural Language Prompts: Describe desired data in plain English rather than writing CSS selectors or XPath
-
Transparent Credit-Based Pricing: 1 credit = 1 page for standard scraping (some optional features like stealth proxies may use additional credits)
-
Native AI Framework Integrations: Direct connectors for LangChain and LlamaIndex
-
Zero-Selector Paradigm: AI-powered semantic extraction that's more resilient to website changes
Why Choose Firecrawl Over Octoparse for AI-Native Extraction
Firecrawl serves a different use case than Octoparse:
-
Purpose-Built for LLM Workflows
Octoparse outputs data for spreadsheets, databases, and BI tools. Firecrawl formats content specifically for language model consumption. When Octoparse extracts a product listing, it structures data for human analysis. When Firecrawl extracts the same page, it formats content to minimize token usage and maximize semantic coherence for AI processing.
-
API-First Developer Experience
Octoparse's no-code interface can introduce friction for developers building programmatic AI pipelines. Firecrawl's API-first design means developers can initiate scraping with straightforward code, receive webhooks on completion, and integrate web data collection into existing codebases. Official SDKs support Python and Node.js.
-
Semantic Zero-Selector Extraction
Traditional scrapers rely on CSS selectors that break when websites change. Firecrawl uses AI to understand semantic content, allowing natural language descriptions of desired data. This approach claims 93.7% ROUGE scores in benchmarking and is more resilient to cosmetic website changes than selector-based methods.
🏅 NOTE: We also evaluated Crawl4AI and ScrapeGraphAI for AI-native scraping. While these represent interesting open-source options, Firecrawl offers the most mature product with Y Combinator backing, $14.5M in Series A funding, and comprehensive documentation for production AI applications.
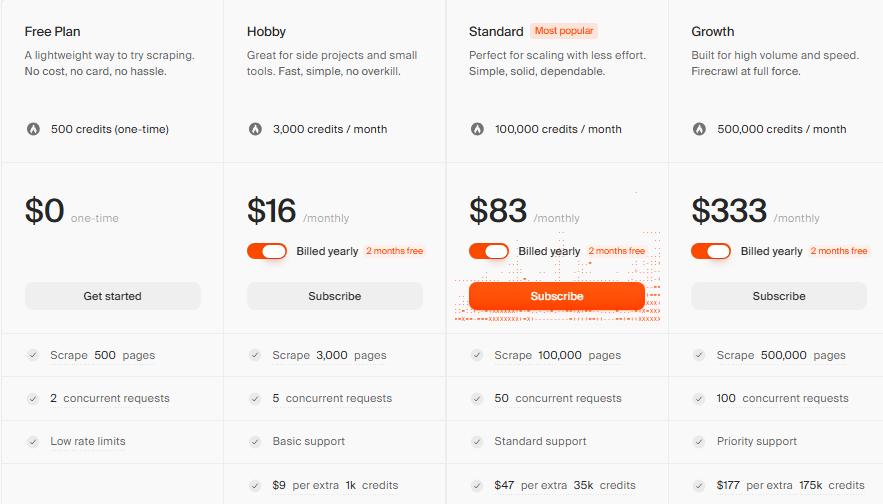
Firecrawl Pricing
-
Free: $0, 500 one-time credits, 2 concurrent requests
-
Hobby: $16/month (annual), 3,000 credits/month, 5 concurrent requests
-
Standard: $83/month (annual), 100,000 credits/month, 50 concurrent requests
-
Growth: $333/month (annual), 500,000 credits/month, 100 concurrent requests
Source: Firecrawl
Who Should Use Firecrawl?
Choose Firecrawl if:
-
You're building AI or LLM applications. Markdown output and framework integrations make Firecrawl purpose-built for RAG systems and AI agents.
-
Your team prefers code over visual interfaces. The API-first approach integrates naturally into development workflows.
-
You need scraping that's more resilient to website changes. Semantic extraction is generally more durable than selector-based approaches.
The Final Verdict
While Octoparse excels as an accessible, visual web scraping tool, different data needs require different solutions. Based on our research, here are the best alternatives:
-
GetRealPrice for e-commerce businesses that need competitive pricing intelligence delivered as insights, not raw data requiring technical processing
-
Bright Data for enterprise teams requiring massive proxy infrastructure scale and developer control
-
Apify for growing teams that need both marketplace convenience and developer flexibility, especially for AI applications
-
ParseHub for small teams validating web scraping feasibility with minimal financial commitment
-
Browse AI for users who need self-maintaining scrapers and website change monitoring
-
Scrapy for Python developers who want complete control and zero licensing costs
-
Firecrawl for AI engineers building LLM applications that need web data in optimized formats
Remember, these alternatives serve different purposes.
Some users might continue using Octoparse for general scraping while adding a specialist tool like GetRealPrice for competitive intelligence. Others might replace Octoparse entirely with a solution better suited to their technical resources and data requirements.
Consider your specific needs, technical capabilities, and growth plans when deciding which solution works best for you.
Ready to transform competitive pricing from a technical project into strategic intelligence? GetRealPrice delivers human-verified product matching, automated pricing recommendations, and competitor insights without the scraper maintenance. Request a demo to see how purpose-built e-commerce intelligence compares to DIY data extraction.